

Mixture-of-Depths: AI’s Next Leap Beyond MoE Models

Is Half Your AI Compute Wasted?
Did you know that in many large language models, up to 50% of the computational power used during inference might be unnecessary? We often assume that for an AI to be smarter, it must be bigger and use more power for every single task. But what if that’s not true? The current approach, used in both standard dense models and even advanced Mixture-of-Experts (MoE) models, forces every piece of information, or token, through a fixed amount of processing. This is like making a world-class chef use a 10-step recipe for both a complex dish and for boiling water. It’s incredibly inefficient. This is the problem that the new Mixture-of-Depths (MoD) transformer architecture is built to solve. It introduces a dynamic compute method that could redefine LLM efficiency for years to come.
The Core Building Blocks of MoD
To understand what makes Mixture-of-Depths work, you need to know its key parts. It’s not a complete reinvention of the wheel but a very clever modification of the existing transformer architecture.
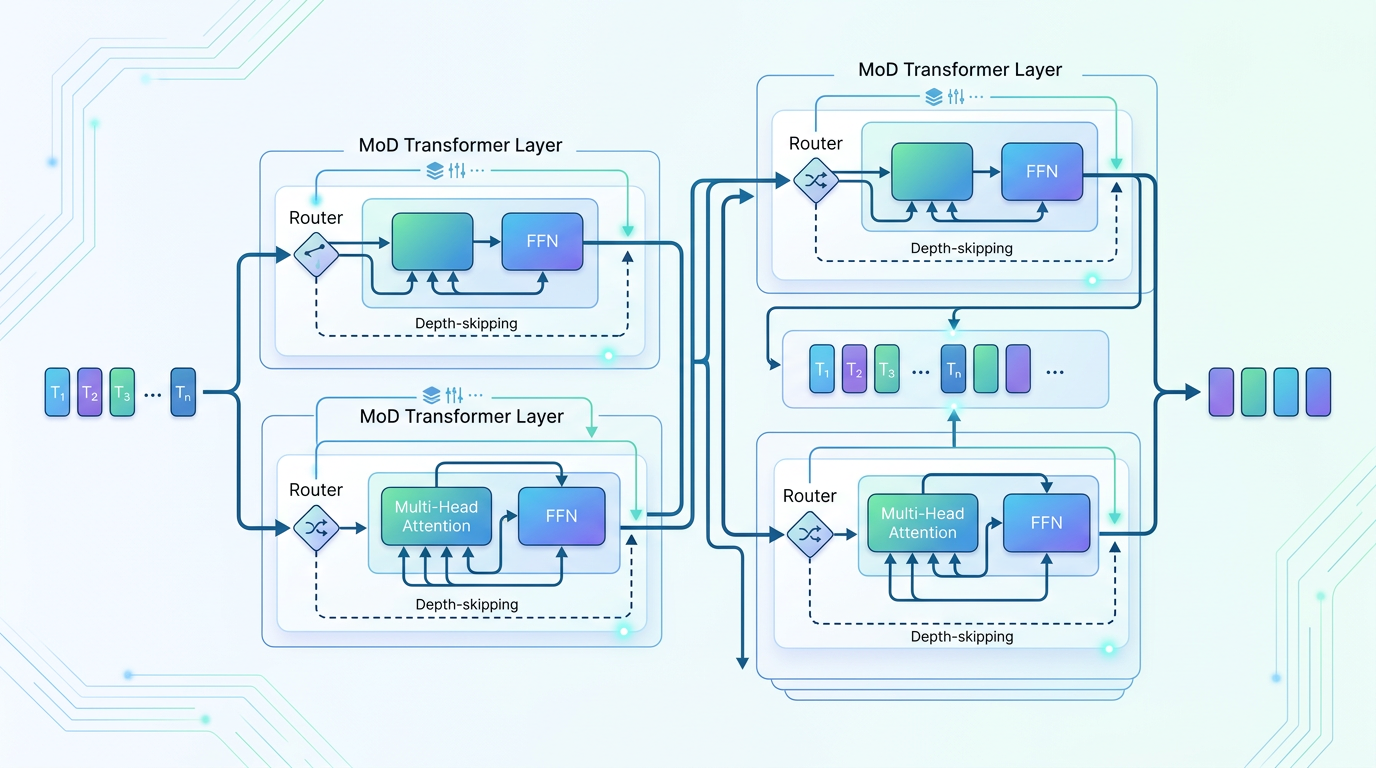
- Standard Transformer Blocks: These are the fundamental layers of any modern LLM. Each block contains self-attention and feed-forward networks that process the data. In MoD, the model has a very large number of these blocks, creating a massive ‘potential depth’.
- Depth Routers: This is the secret sauce. At specific points in the model (for example, every few layers), a small, lightweight neural network called a ‘router’ inspects each token. Its only job is to decide: does this token need more processing, or is its meaning clear enough to stop here?
- Early Exiting Mechanism: If a router decides a token is ‘done’, that token gets to ‘exit early’. It bypasses all the remaining transformer blocks, saving a huge amount of computation. Its final representation is then carried forward to the end.
The main alternatives MoD improves upon are standard dense models, where every token goes through every layer, and Mixture-of-Experts (MoE) models, which route tokens to different ‘expert’ networks at each layer but still send every token through the same number of layers.
How Much Time and Compute Does MoD Actually Save?
The big win for Mixture-of-Depths isn’t during training, which is still a big job, but at inference time. This is the stage when you are actually using the model to get answers, generate text, or analyze data. Here, the savings are massive.
According to the original research paper from Google (arXiv:2404.02258), an MoD model can match the quality of a standard transformer while using up to 50% fewer floating-point operations (FLOPs). Think about what that means. A query that would take a powerful model 2 seconds to answer might be completed in just 1 second with MoD, because half the tokens in the query were simple and didn’t need the full computational journey.
For example, in a sentence like ‘The cat sat on the mat,’ the tokens ‘The’, ‘on’, and ‘the’ are simple. An MoD model might process them through only 30% of its total layers. In contrast, a word like ‘photosynthesis’ in a scientific document would be routed through many more, perhaps all, of the model’s layers to capture its full meaning. This dynamic compute allocation is what makes it so fast and efficient.
Step 1: Understand the Static Compute Problem
First, picture a standard transformer model. When you feed it a sentence, it breaks it down into tokens. In models like GPT-3 or Llama, every single token, from a simple ‘a’ to a complex term like ‘epigenetics’, travels through the exact same number of computational layers. This is static compute. It’s predictable but wasteful. MoE models improved this by choosing different experts, but the depth remained fixed.
Step 2: Grasp the ‘Early Exit’ Concept
Now, imagine a highway with many exits. This is the MoD model. Each transformer block is like a mile of highway. Simple tokens are like cars with a short commute; they can take an early exit. Complex tokens are like long-haul trucks; they stay on the highway for the entire journey. MoD allows each token to travel only as far as it needs to, saving ‘fuel’ (compute) for tokens that don’t need the long trip.
Step 3: See How Routers Make Decisions
How does a token know when to exit? At certain layers, a ‘router’ looks at the token’s current state (its embedding). During the model’s training, this router learns to predict whether further processing will meaningfully change the token’s representation. If it predicts little change, it assigns the token a high probability to exit. If the token is still ambiguous, the router tells it to keep going. It’s a learned, probabilistic decision.
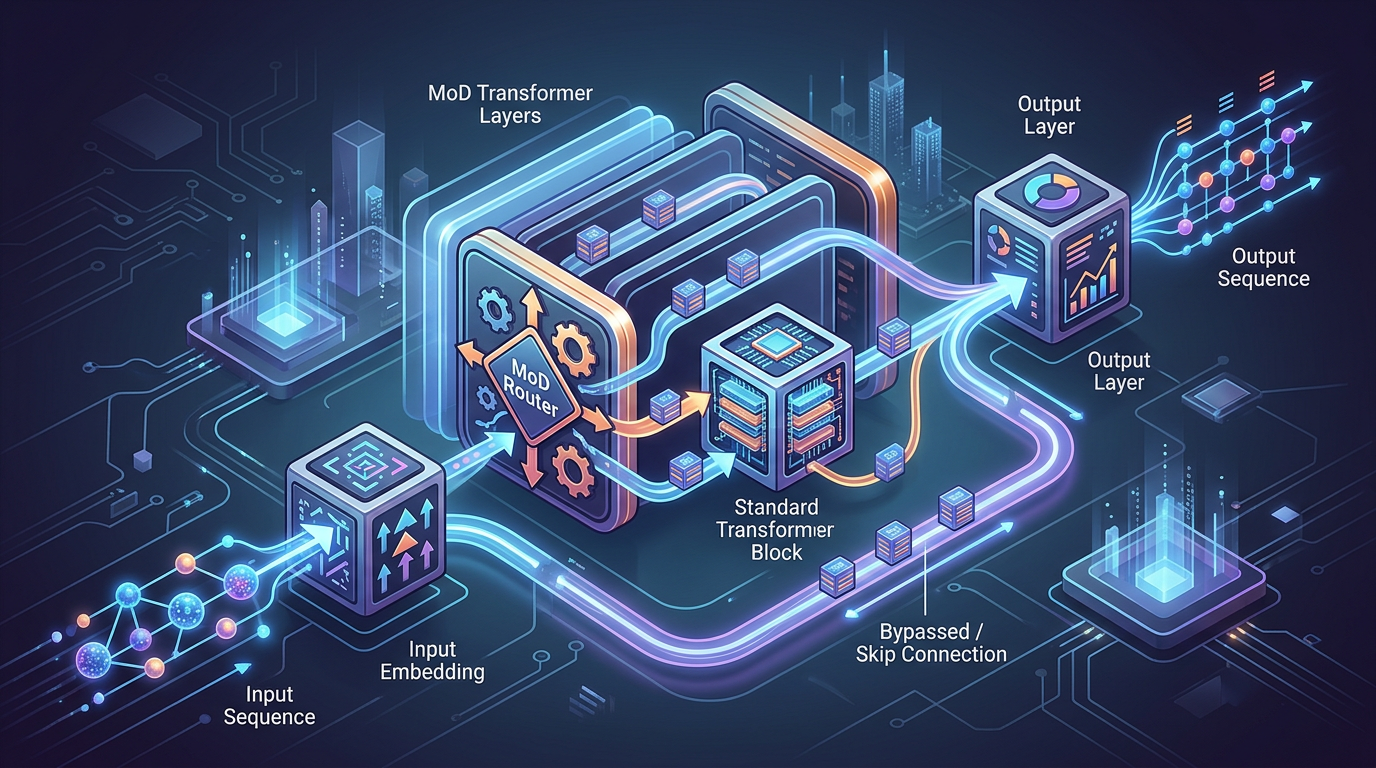
Step 4: Combine Token Representations at the End
What happens to the tokens that exit early? They don’t just disappear. Their final computed state is preserved and carried forward to the very end of the model. The model then combines the representations of all tokens, whether they went through 20 layers or 100, to produce the final output. This ensures the model’s full context and power are maintained, even though the average compute per token is drastically lower.
MoD Performance by the Numbers
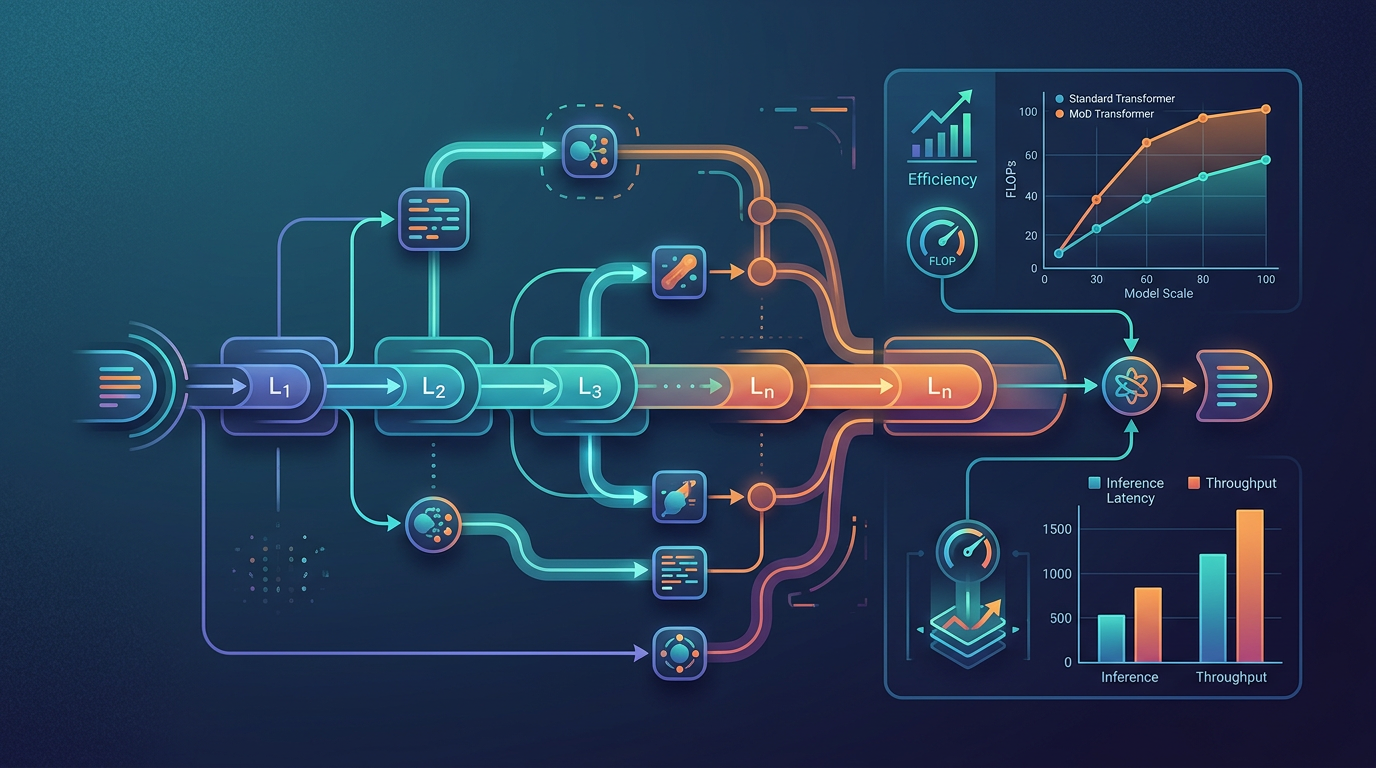
The data from the initial research is compelling. Mixture-of-Depths isn’t just a small improvement; it’s a major step in LLM efficiency. Here are the key performance metrics that matter:
- Inference FLOPs Reduction: MoD uses up to 50% fewer computational FLOPs during inference compared to a dense transformer of equivalent quality.
- Performance Parity: For the same amount of inference compute, MoD models show significantly better performance (lower perplexity scores) than standard transformers.
- Training Stability: The training process for MoD is reported to be stable, using load-balancing techniques similar to those in MoE models to ensure routers don’t develop bad habits, like sending all tokens to the first exit.
- Potential vs. Actual Depth: This is a new way to think about model size. An MoD model might have a ‘potential depth’ of 128 layers, but the average token only ‘sees’ 40-60 of them. This allows models to be theoretically huge without the full inference cost.
Here’s a simple comparison of the architectures:
| Architecture | Compute Per Token | Path Flexibility | Best For |
| Dense Transformer | Fixed (High) | None (Static Path) | Simplicity, smaller models |
| Mixture-of-Experts (MoE) | Fixed (Lower than Dense) | Horizontal (Chooses different experts) | Scaling model width efficiently |
| Mixture-of-Depths (MoD) | Variable (Low on average) | Vertical (Chooses different depths) | Maximum inference efficiency |

How MoD Stacks Up: Dense vs. MoE
To really appreciate Mixture-of-Depths, it helps to compare it directly with the architectures that came before it.
Dense Models: The Old Faithful
This is the classic transformer architecture. It’s strong and reliable. Its main weakness is its brute-force approach. Every token goes through every single layer, no exceptions. This makes scaling very expensive. A 100-layer model does 100 layers of work for every token, always.
Mixture-of-Experts (MoE): The Horizontal Expansion
MoE was a big breakthrough. Instead of one giant feed-forward network in each layer, it has several smaller ‘experts’. A router picks one or two experts for each token to visit. This was a great way to increase model parameter count without a proportional increase in compute. However, every token still passes through the same number of layers from start to finish. MoE routes tokens sideways, not shorter.
Mixture-of-Depths (MoD): The Vertical Revolution
MoD takes the routing idea from MoE but applies it vertically. Instead of asking ‘which expert should this token see?’, it asks ‘should this token see any more layers at all?’. This dynamic depth allocation is a fundamentally new way to save compute. The trade-off is a bit more complexity in the model design, but the inference speed and cost savings are a game-changer.
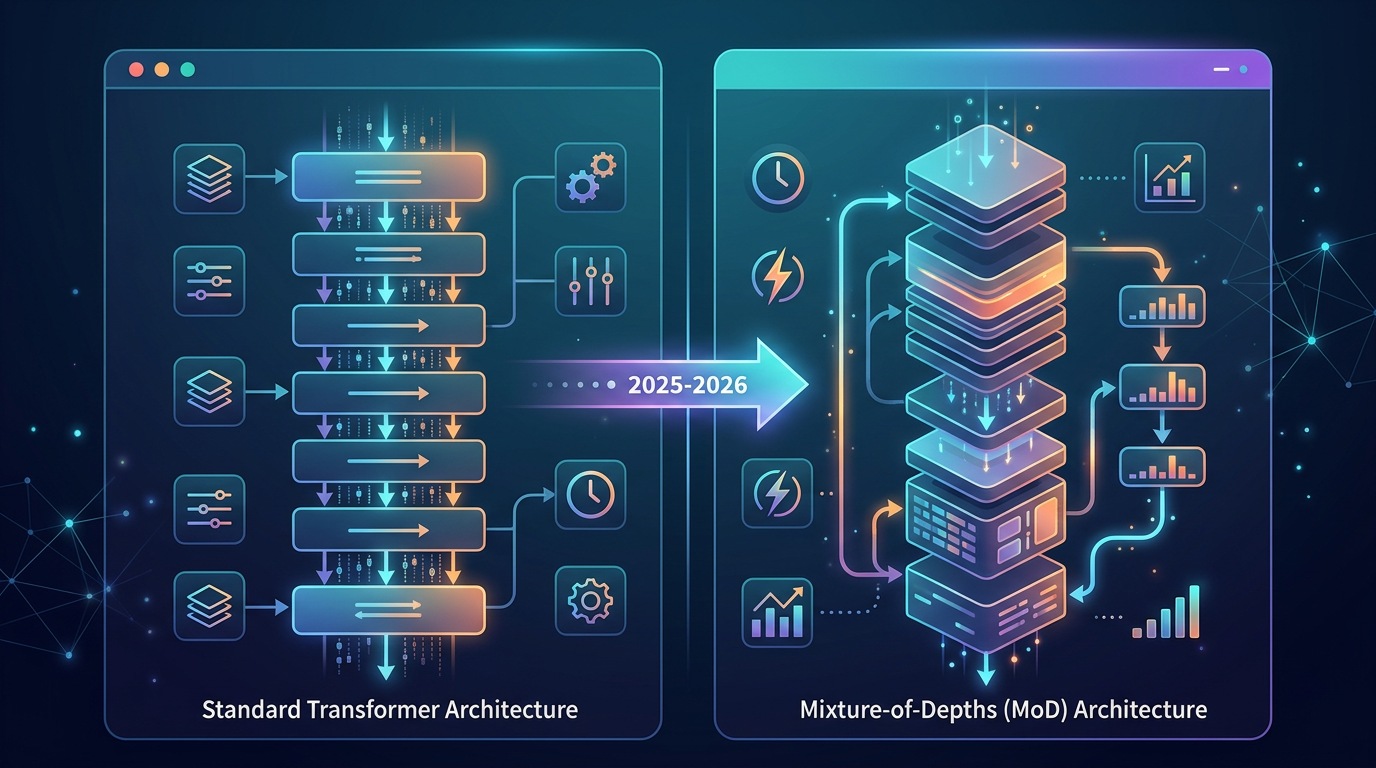
Where We’ll See MoD in Action (2025-2026)
This isn’t just a theoretical AI research paper. The principles of Mixture-of-Depths are so powerful that they are almost certain to become a standard for next-generation models. Here’s where you can expect to see its impact:
- Flagship Foundation Models: The next versions of models from Google, OpenAI, Anthropic, and others will likely use MoD or similar dynamic compute architectures. It allows them to build even more capable models while keeping inference costs from spiraling out of control.
- Powerful On-Device AI: The efficiency of MoD could be the key to running truly powerful AI models directly on your smartphone or laptop. This enables better privacy and real-time responsiveness for personal assistants and other apps, without needing to constantly connect to the cloud.
- Accelerated Scientific Discovery: For researchers working with huge datasets, like in genomics or climate science, MoD can speed up analysis. The model can quickly process the simple, redundant data points and dedicate its full power to the complex, novel patterns that lead to new discoveries.
- Affordable Real-Time Services: Applications like live translation, customer service chatbots, and content moderation can become cheaper and faster. The model can handle the easy parts of a conversation instantly, making the user experience feel seamless.
Mistakes to Avoid When Thinking About MoD
As with any new technology, some misconceptions are bound to pop up. Here are a few common mistakes I see people making when discussing Mixture-of-Depths.
Mistake 1: Confusing MoD with MoE. Many people hear ‘Mixture-of’ and assume they’re the same. They are related, but MoE is about routing tokens to different experts (width), while MoD is about routing tokens to different exit points (depth). The efficiency gains come from completely different strategies.
Mistake 2: Assuming it’s a ‘free lunch’. MoD provides huge savings, but it’s not without cost. The routers themselves add parameters and require computation. The training process is also more complex. The magic is that the cost of routing is very small compared to the massive savings from skipping entire transformer blocks.
Mistake 3: Thinking it makes training cheaper or faster. The main benefit of MoD is realized at inference time. The training process is still very demanding. The model must learn not only how to perform tasks but also how to optimally route tokens. This training cost is likely similar to a large MoE model.
Preparing for a Future with MoD
The rise of dynamic compute architectures like MoD will change how we develop and deploy AI. Here are a few ways to prepare for this shift.
For Developers: Get comfortable with the concepts of conditional computation. Start by exploring open-source MoE implementations, which are widely available on platforms like Hugging Face. Understanding the routing and load-balancing logic in MoE is a perfect stepping stone to grasping MoD.
For Business Leaders: When you budget for AI initiatives in 2025 and beyond, understand that the cost of using top-tier models might not grow as fast as their capabilities. MoD could lead to lower, more predictable operational costs for AI-powered products, making more ambitious projects financially viable.
For Researchers: The next big area of AI research will likely involve improving the routers. The ‘intelligence’ of an MoD model is in its ability to know when a token is ‘done’. Designing more efficient and accurate routing algorithms is where the next wave of innovation will come from.
Wrapping Up
A New Era of Efficient AI
Mixture-of-Depths is more than just another tweak to the transformer. It’s a change in philosophy, from brute-force computation to intelligent, dynamic allocation. This promises a future of faster, cheaper, and more accessible AI for everyone. What will you build with it? Share your ideas in the comments!
Found this helpful? Share your thoughts in the comments below, and subscribe to our newsletter for more AI insights delivered to your inbox.
Frequently Asked Questions
What is the main difference between Mixture-of-Depths (MoD) and Mixture-of-Experts (MoE)?
The main difference is the dimension they optimize. Mixture-of-Experts (MoE) routes tokens ‘horizontally’ to different expert networks within each layer. Mixture-of-Depths (MoD) routes tokens ‘vertically’, allowing them to exit the model early and skip subsequent layers. MoE varies the ‘who’ of computation, while MoD varies the ‘how much’.
Does MoD make AI models smaller?
Not exactly. In fact, an MoD model can have a very large ‘potential’ size in terms of its total number of layers and parameters. However, it acts ‘small’ during inference because the average token only uses a fraction of that total size. It’s about being more efficient with the size you have, not necessarily reducing it.
Will Mixture-of-Depths reduce the cost of using models like GPT-5?
It is very likely. The primary benefit of MoD is a massive reduction in inference compute (FLOPs), which directly translates to lower energy consumption and operational costs. We can expect future flagship models to use MoD-like architectures to deliver more power at a lower cost per query for users.
Is MoD a theoretical concept or is it being used now?
As of mid-2024, Mixture-of-Depths is primarily a research concept introduced by Google. However, given its significant advantages, it is widely expected to be integrated into the next generation of large-scale foundation models between 2025 and 2026.
How does an MoD model decide which tokens are ‘simple’ or ‘complex’?
This is learned during the training process. The model has small ‘router’ networks placed at intervals. These routers analyze a token’s representation and predict if more processing will significantly improve its meaning. If not, the router directs the token to exit early. This decision-making ability is optimized automatically during training.
Can I build my own Mixture-of-Depths model today?
While there isn’t a simple, one-click library for MoD yet, the concepts are based on existing transformer and MoE frameworks. An experienced machine learning engineer could implement a simplified version by modifying open-source codebases like PyTorch or JAX and creating custom routing modules. It is an advanced task but technically feasible.
Sources & References
- https://arxiv.org/abs/2404.02258 (Mixture-of-Depths: Dynamically allocating compute in transformer-based language models)
- https://huggingface.co/blog/moe (Explanatory article on Mixture of Experts for background context)
- https://ai.google/discover/research/ (Google AI research blog for official announcements and context)
Search Trending News
Recent News
- NVIDIA Chimera: A Quantum Leap for AI Hardware?

- Amazon Echo Scribe: The AI Pin Killer Is Officially Here?

- Siri Pro: Apple’s On-Device AI Arrives with iOS 19

- Mixture-of-Depths: AI’s Next Leap Beyond MoE Models

